I'll leave here my notes about the basics on html, css and javascript integration, some pieces of code exemplifying them, and a bit of HTML5 and CSS3.
I won't explain what is html, css and js, and it's structures. If you don't have the basics concepts, you'd better not continue to read this post.
CSS Addressing HTML Elements
First thing: keep your CSS code in a separate file. Don't use embedded in your HTML file. This way you can have a standard code, reusable, making it easy to maintain.
There are three ways to address HTML elements on your CSS:
- Directly to a specific element type. For example, if you want all <h1> elements to have a font-size with 25 pixels, just create on your CSS a piece of code like the following one:
h1 {
font-size: 25px;
} - Specify a class to be used as a tag attribute on the HTML file. First, create the class on the CSS file - starts with a dot:
.blue_paragraph {
background-color: blue;
}
Then, refer to these class within the HTML file:
<p class="blue_paragraph"> - Refer directly to a id attribute on a HTML element:
<p id="main_paragraph">
So, on CSS it addresses the id - the hash has to be used before the id name on the CSS file:
#main_paragraph {
font-size: 25px;
}
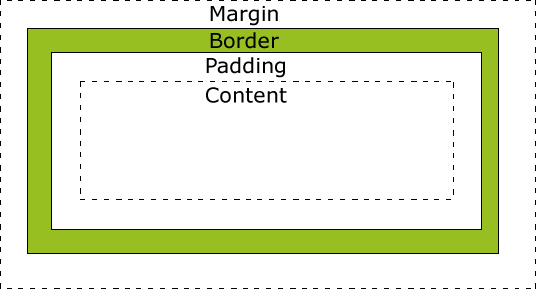
The Box Model is another important thing to be highlighted. For the border, it is possible to specify how thick it is. For the margin and padding, it defines the spacing inside and outside the box. You can use in two ways, removing the whole margin:
margin: 0px;
or defining jus the top, left, right or bottom:
margin-top: 0px;
JavaScript Important Notes
First thing: keep your JS code in separate files. Don't use embedded in your HTML file. Document your code as much as you can. This way you can have a standard code, reusable, making it easy to maintain.
Make use of the console. When you use Chrome, i.e., on the "Inspect Element" option, you can view the Console. Within the JavaScript, make use of it to print values, variables, comments, by using:
console.log('Hello');
Have a list of all available events available, like the following one:
http://www.quirksmode.org/dom/events/index.html
Make use of objects, translate them into a JSON document when necessary:
var user = new Object();
user.name = 'Pedro';
user.lastName = 'Catoira';
var jsonObject = JSON.stringify(user);
New Features on CSS3
The new pseudo-classes target elements based on their position in the document:
- :root – targets the root element of a document;
- :only-child – element in the document tree that is the only child of its parent;
- :empty – targets elements that don’t have any children or any text, like <h1></h1>;
- :nth-child(n) – targets child elements in relation to their position within the parent, using an index;
- :first-of-type – targets the first of a specific type of element within a parent, and is the opposite of :last-of-type;
- :first-child – targets the first child element in a parent. It is the opposite of :last-child;
- :not(s) – this one targets elements that are not matched by the specified selector.
Vendor prefixes helps browsers interpret the code. Below is a short list with all the vendor prefixes for major browsers:
- -moz- : Firefox
- -webkit- : Webkit browsers such as Safari and Chrome
- -o- : Opera
- -ms- : Internet Explorer
Rounded corners without images and JavaScript is one of the biggest features of CSS3, we can do this with only a few lines of code:
#my_id { height: 100px;
width: 100px;
border: 1px solid #FFF;
/* For WebKit: */
-webkit-border-radius: 15px;
}
#my_id { height: 100px;
width: 100px;
border: 1px solid #FFF;
/* For WebKit: */
-webkit-border-radius: 15px;
}
Border images allow developers and designers to take there site to the next level without the need to create images:
#id_xyz
/* url, top image, right image, bottom image, left image */
border-image: url(border.png) 30 30 30 30 round round;
}
Before CSS3, we had to either use a shadow image or JavaScript to apply a shadow or create the shadow directly in the image. With CSS3 Box Shadow we can apply shadows to almost every element of our website:
#id_xyz
background: #FFF;
border: 1px solid #000;
/* For WebKit: */
-webkit-box-shadow: 5px #999;
}
With the Multi-Column Layout, it's possible to arrange text in more of a “news paper” type way. You have the choice to pick the amount of columns, the column width, column gap width, and column separator:
#id_xyz
text-size: 12px;
/* For WebKit: */
-webkit-column-gap: 1em;
-webkitcolumn-rule: 1px solid #000;
-webkit-column-count: 3;
}
Create multiple backgrounds on a single element:
#id_xyz {
background:
url(topbg.jpg) top left no-repeat,
url(middlebg.jpg)center left no-repeat,
url(bottombg.jpg) bottom left no-repeat;
}
@font-face - The new CSS3 implementation allow developers and designers to use any licensed TrueType “.tff” or OpenType “.otf” ” in their web designs:
@font-face {
font-family: "my-font";
src: url(my-font.tff) format("truetype");
}
#id_xyz {
font-family: "my-font", sans-serif;
}
In CSS3, three additional attribute selections are available for matching substrings of the attribute value:
Select elements with title prefix of “x”:
p[title^=x] {
(...)
}
Select elements with title suffix of “x”:
p[title$=x] {
(...)
}
Select elements with title contain at least one instance of “x”:
p[title*=x] {
(...)
}
Opacity is also supported:
#id_xyz {
background: #F00;
opacity: 0.5;
}
RGBA Colors:
#id_xyz {
background: rgba(255, 212, 45, 0.5);
}
But you don't really have to have all of that in mind. Just have to know the capabilities. These are helpful sites to support nice CSS code:
- to generate the CSS code for coloring:
http://www.colorzilla.com/gradient-editor/ - to generate the CSS code for some nice effects:
http://css3generator.com/
New Features on HTML5
The list of new features on HTML5 is huge. In summary, it's trying to simplify what we had before, and also adding some new important features. Here are some of them:
- Simple Doctype - just need this now:
<!DOCTYPE html> - The new elements:
http://www.w3schools.com/html/html5_new_elements.asp; - The type attribute is not required anymore for script and link tags;
- Editable contents:
<h2> To-Do List </h2>
<ul contenteditable="true">
<li> Break mechanical cab driver. </li>
<li> Drive to abandoned factory
<li> Watch video of self </li>
</ul> - Small validations, like testing the typed e-mail account, now is available on HTML5. That makes the browser to test it and display an error message without submitting the form:
<form action="" method="get">
<label for="email">Email:</label>
<input id="email" name="email" type="email" />
<button type="submit"> Submit Form </button>
</form> - Regular Expressions:
<input type="text" name="username"
placeholder="4 <> 10"
pattern="[A-Za-z]{4,10}"/> - Required and Autofocus attributes:
<input type="text" name="email" required autofocus> - Native placeholders for input boxes:
<input name="email" placeholder="jdoe@gmail.com" /> - Local Storage is the feature on HTML5, in combination to JavaScript, that allows data to be saved offline, like in the example below:
localStorage.clear();
localStorage.setItem('names', variable);
console.log(localStorage.getItem('names'));


